How to Install and Use Whisper by OpenAI to Convert Video to Text
• Updated Aug 13, 2025 • Rasim Mahmudov • 13 min read
• 8672 views • 0 comments
Step 1: Install Whisper
First, you’ll need Python installed (version 3.8+ recommended).
To install Whisper, open your terminal or command prompt and run (You can use anaconda for isolated environment):
pip install -U openai-whisper
✅ Tip: If you don't have pip or Python, download Python here.
Step 2: Install ffmpeg
Whisper needs ffmpeg to handle video and audio files.
Install it with:
# For Ubuntu/Debian brew install ffmpeg # For Mac (with Homebrew) choco install ffmpeg # For Windows (with Chocolatey)
sudo apt install ffmpeg
Or you can manually download ffmpeg from ffmpeg.org.
*Note the above link will redirect you to a github page and you can download appropriote one for your operating system.
I selected: ffmpeg-master-latest-win64-gpl.zip
Download the binary edition (zip/rar archive) and extract the files into C:\ffmpeg
There should be three files named: ffmpeg.exe, ffplay.exe and ffprobe.exe
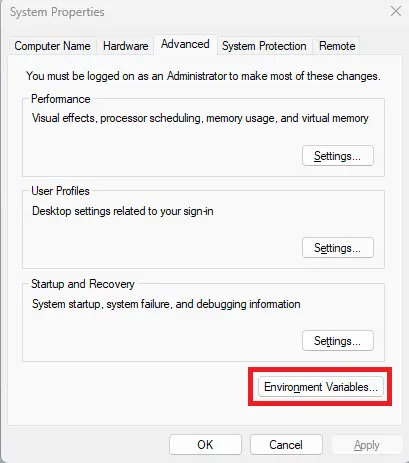
Then you must add the ffmpeg path (C:\ffmpeg\) to the system environment variables.
Search for "View advanced system settings" and open it.
And here you should select: System variables > Path > Edit > New > "C:\ffmpeg" > OK
Now you should be able to invoke ffmpeg on Command Prompt (cmd.exe).
*Note: If you had already opened cmd.exe before adding ffmpeg, you should reopen cmd.exe to see the taken effect.
Step 3: Convert Your Video to Text
Now, you can easily convert any video file to text with just one command.
Example:
whisper your_video.mp4 --model small
Replace your_video.mp4 with your file name.
Example result:
The output will be your_video.txt file automatically created in the same folder!
Bonus: Full Python Script to Use Whisper Programmatically
Want to do it inside a Python script?
Here’s a simple example:
import whisper
model = whisper.load_model("base") # You can also use "small", "medium", or "large"
result = model.transcribe("your_video.mp4")
print(result["text"])
✅ This script will print the full text transcription!
All models and comparison among them are given below:
Model
Parameters
Size on Disk
Speed
Accuracy
Hardware Need
Typical Use Case
Tiny
39M
~151 MB
Very Fast
Lowest
Very Low
Real-time apps, mobile devices
Base
74M
~290 MB
Very Fast
Low-Mid
Low
Faster decoding with slightly better quality
Small
244M
~967 MB
Fast
Medium
Medium
Good quality at a reasonable speed
Medium
769M
~2.9 GB
Moderate
High
High
Higher accuracy needs, server-side apps
Large
1550M
~5.8 GB
Slowest
Best
Very High (Strong GPU recommended)
Best quality transcription, multilingual, research
Optional: Whisper Command Line Options
Here are some handy extra options you might like:
Option Description
--language English Set the language manually
--task translate Translate speech to English
--output_format txt Save output as .txt
--model small Use a smaller, faster model
Example command:
whisper your_video.mp4 --language English --task translate --output_format txt --model small
Input: lesson1.mp4
Outputs (all):
lesson1.json (timing in json)
lesson1.srt (with timing)
lesson1.tsv (start end timestamp)
lesson1.txt (Only text)
lesson1.vtt (with timing)
Final Thoughts
Whisper is super powerful and surprisingly easy to use once you set it up.
You can automate transcriptions, translations, and even batch process tons of videos!
Happy transcribing! ✨

 The output will be your_video.txt file automatically created in the same folder!
Bonus: Full Python Script to Use Whisper Programmatically
Want to do it inside a Python script?
Here’s a simple example:
The output will be your_video.txt file automatically created in the same folder!
Bonus: Full Python Script to Use Whisper Programmatically
Want to do it inside a Python script?
Here’s a simple example:
0 Comments
No comments yet, be the first!
Leave a Comment